The promise of agentic AI systems—autonomous agents capable of reasoning, planning, and taking action—hinges on a fundamental assumption that often goes unexamined. We assume these systems will perform better with more data. But enterprise deployments reveal a different truth: agents fail not because they lack data, but because the data they consume lacks the quality, context, and trustworthiness required for reliable autonomous operation.
This misconception has real consequences. Organizations invest heavily in data collection and storage while overlooking the quality foundations that determine whether their agentic systems will succeed or become expensive liability generators.
The High-Fidelity Data Imperative
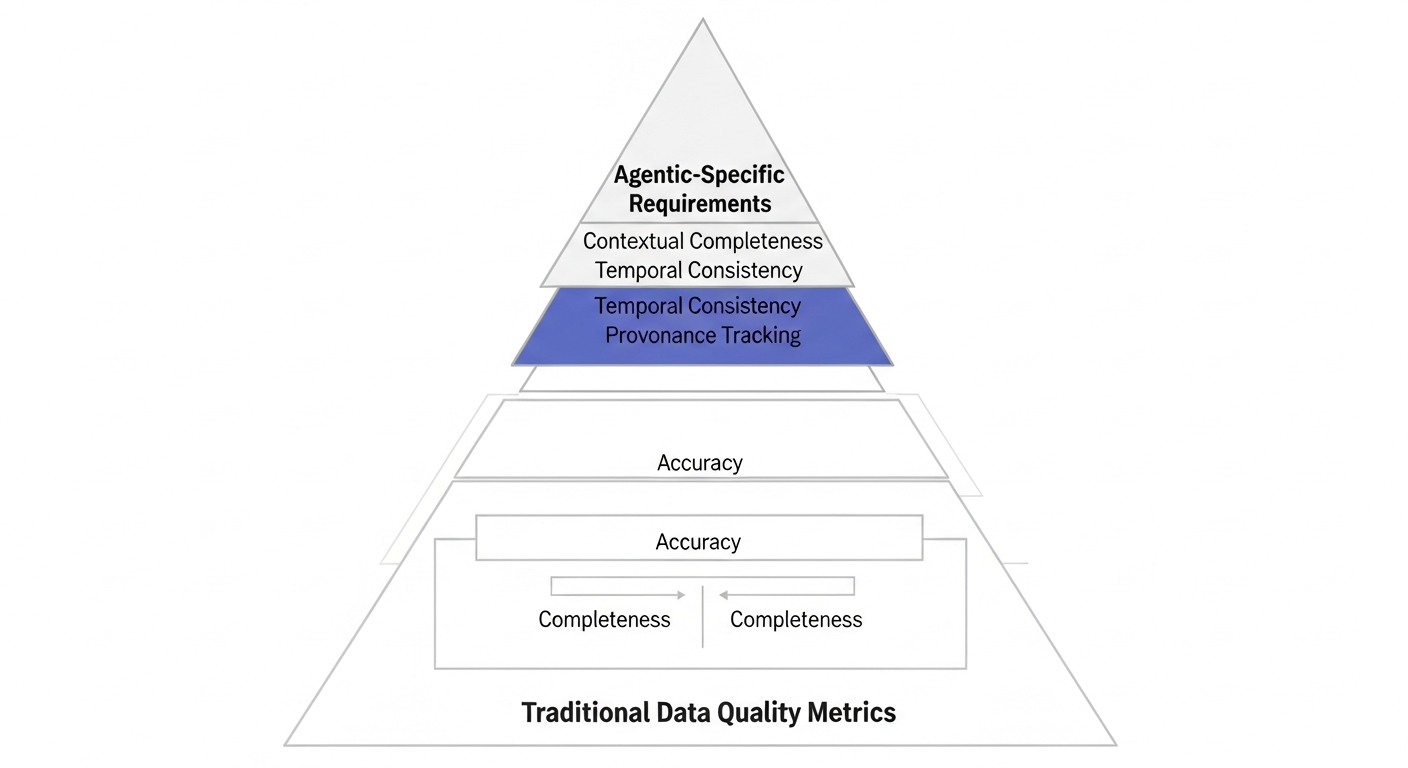
High-fidelity data for agentic systems goes beyond traditional data quality metrics. While accuracy and completeness matter, autonomous agents require additional dimensions of quality that human-supervised systems can often work around.
Contextual completeness becomes critical when agents must understand not just what happened, but why it happened and under what conditions. A customer service agent needs to know that a refund request came after a delayed shipment during a supply chain disruption, not just that a refund was requested.
Temporal consistency ensures that agents understand the sequence and timing of events. Financial trading agents, for example, need precise timestamps and event ordering to make sound decisions about market movements.
Provenance and lineage tracking allow agents to assess the reliability of their information sources. When an agent receives conflicting data points, understanding the source and processing history helps determine which information to trust.
These requirements exist because agents operate with less human oversight than traditional systems. Where a human analyst might notice that something seems off and investigate further, an agent will proceed with the available data unless explicitly programmed to detect and handle quality issues.
How Poor Data Quality Breaks Agentic Systems
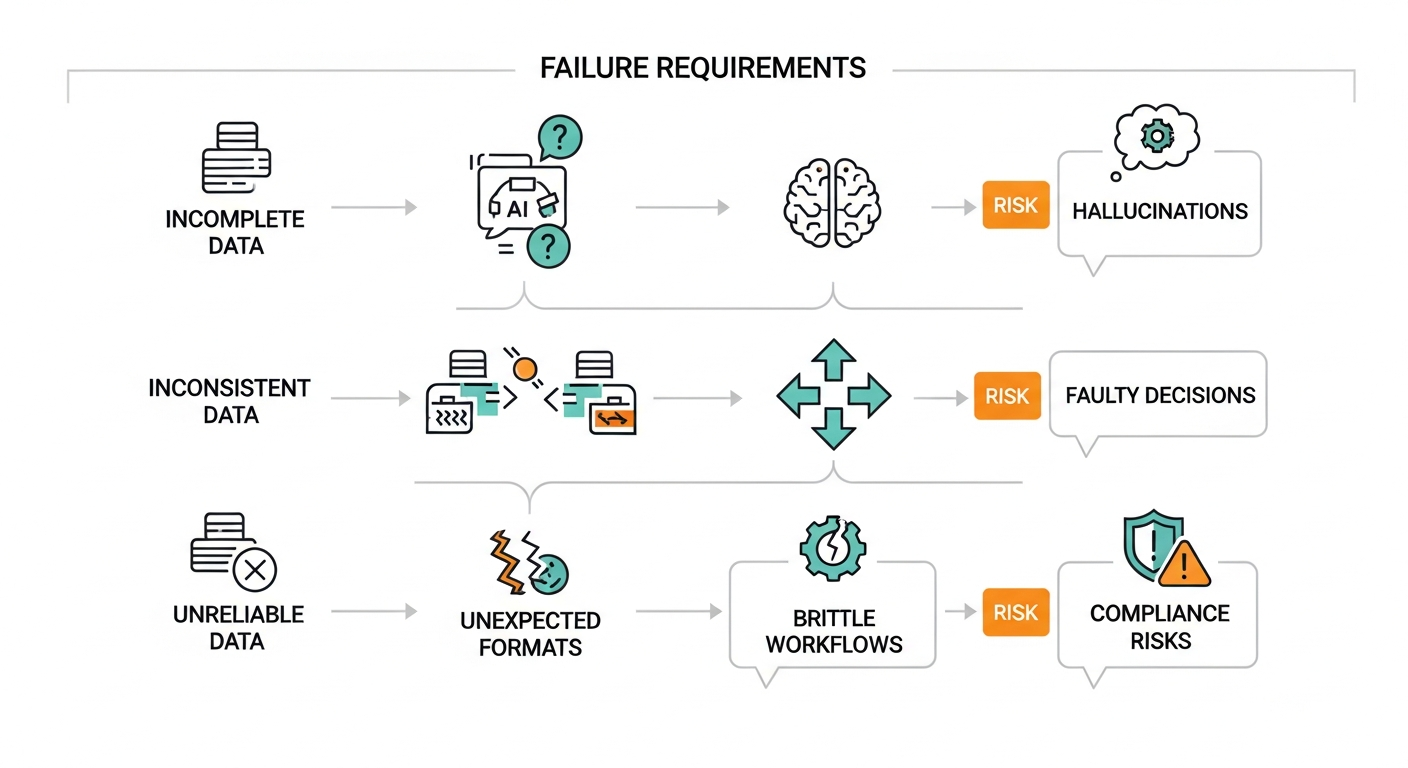
Poor data quality manifests differently in agentic systems than in traditional applications, often with more severe consequences.
Hallucinations occur when agents fill gaps in incomplete data with plausible but incorrect information. A procurement agent working with incomplete supplier data might assume standard payment terms where exceptions exist, leading to cash flow problems and vendor relationship issues.
Faulty decision-making emerges from inconsistent or contradictory data across systems. Consider a logistics agent that receives conflicting inventory counts from warehouse management and ERP systems. The resulting decisions about shipments and restocking can cascade into customer service failures and excess inventory costs.
Brittle workflows develop when agents encounter data formats or values outside their training distribution. A document processing agent trained on clean, structured forms may fail entirely when encountering handwritten notes or non-standard formats, requiring human intervention and defeating the automation purpose.
Governance and compliance risks multiply when agents act on unreliable data. In regulated industries, an agent making compliance decisions based on outdated or incorrect regulatory data can expose the organization to significant legal and financial penalties.
Enterprise Data Reality Check
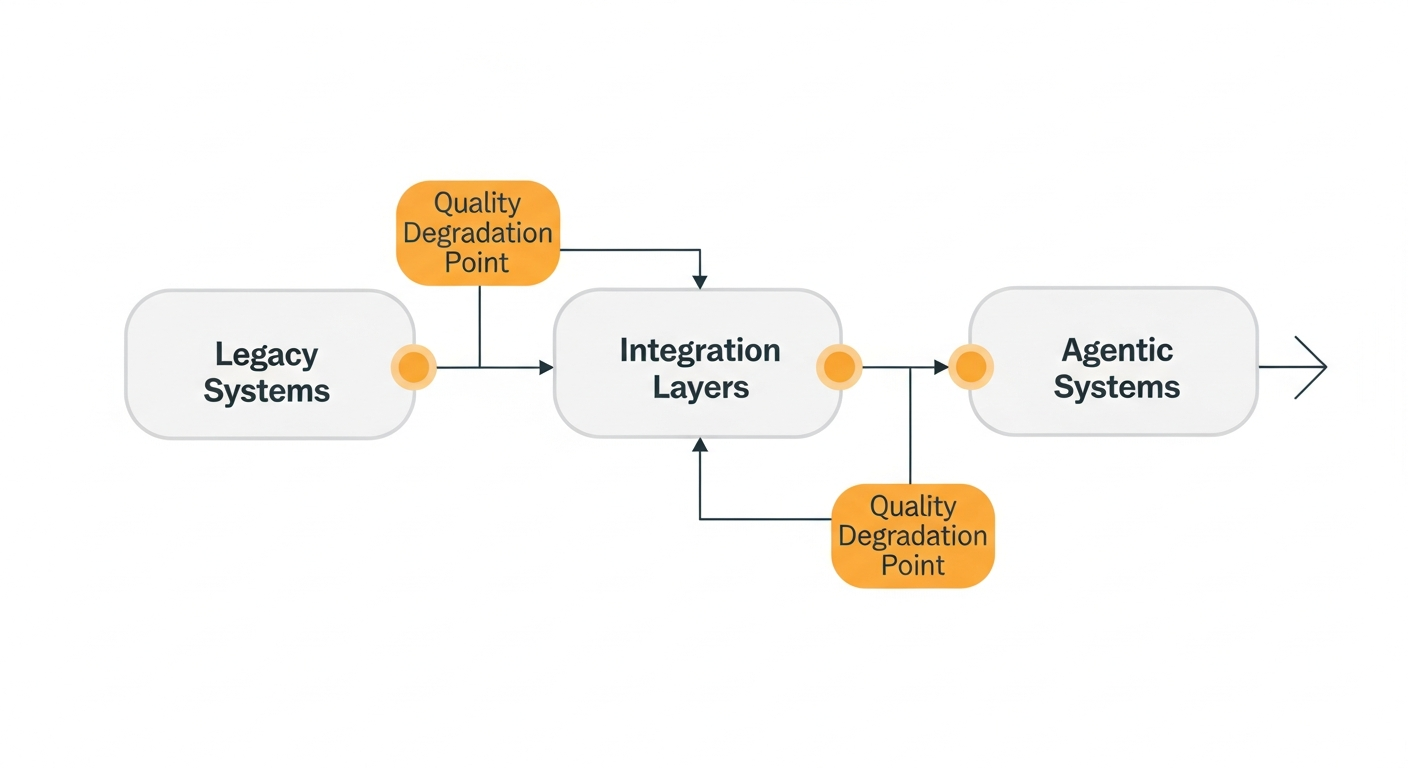
Most organizations face predictable data quality challenges that become amplified in agentic systems. Legacy systems often store data in formats and structures that made sense for their original purpose but lack the context and consistency that agents require.
Data integration across systems frequently introduces quality degradation through field mapping errors, data type mismatches, and timing inconsistencies. A customer record that travels through CRM, billing, and support systems may accumulate inconsistencies that confuse agent reasoning.
Operational processes can introduce systematic quality issues. Manual data entry creates inconsistencies in formatting and completeness. Batch processing systems may process records out of chronological order, breaking the temporal relationships that agents need to understand causation.
These challenges manifest in predictable patterns across enterprise implementations. Consider a scenario where a retailer deploys an inventory management agent that makes restocking decisions based on sales data from multiple channels. If inconsistent product identifiers exist across online and retail systems, the agent might create duplicate inventory records and over-order popular items, potentially resulting in significant excess inventory costs.
Similarly, imagine a financial services firm implementing an agent for loan underwriting that relies on credit bureau data, internal transaction history, and external market data. If timing delays occur in data synchronization, the agent could make decisions based on outdated information, potentially approving loans that should be declined under current market conditions.
Building Data Foundations for Agentic Success
Successful agentic deployments require systematic approaches to data quality that go beyond traditional data management practices.
Data validation must occur at multiple stages, not just at collection points. Real-time validation during agent processing can catch quality issues before they influence decisions. This requires building validation rules that understand the context and expected ranges for different types of agent decisions.
Context preservation becomes crucial for maintaining the semantic meaning that agents need for reasoning. This often means restructuring data storage to maintain relationships and dependencies that may have been flattened in traditional systems optimized for reporting rather than reasoning.
Governance frameworks for autonomous systems must address data quality requirements specific to agent operations. This includes establishing data quality SLAs that reflect agent needs, implementing monitoring systems that can detect quality degradation before it impacts agent performance, and creating rollback procedures for when quality issues are discovered.
Monitoring and feedback loops help identify and correct quality issues in operational systems. Agent performance metrics often serve as early indicators of data quality problems, as agent accuracy and confidence scores typically decline when data quality degrades.
Implementation often requires accepting tradeoffs between data completeness and quality. Organizations may need to use smaller, higher-quality datasets rather than attempting to incorporate all available data sources. The goal shifts from maximizing data volume to optimizing data reliability for the specific reasoning tasks agents must perform.
Conclusion
The transition to agentic AI systems demands a fundamental shift in how organizations think about data strategy. Volume-focused approaches that worked for analytics and reporting often create more problems than they solve when autonomous agents consume that data for decision-making.
Success requires treating data quality as a foundational capability, not an afterthought. Organizations that invest in high-fidelity data foundations before deploying agentic systems will realize the promised benefits of autonomous operation. Those that prioritize data collection over data quality will likely experience the expensive failures that have made many executives skeptical of AI promises.
The path forward involves systematic assessment of current data quality, implementation of agent-specific quality measures, and ongoing monitoring of how data quality impacts agent performance. The investment required is significant, but the alternative is agentic systems that create more problems than they solve.